해당 글은 '[신규 개정판] 이것이 진짜 크롤링이다 - 기본편'을 참고하여 작성한 글입니다.
웹 크롤링이란?
- 웹사이트에 있는 정보를 자동으로 빠르게 수집하는 것
- web(거미줄) + Crawling(기어 다니다)
- 웹스크래핑과 비슷하게 사용됨
웹크롤링 활용
- 데이터 분석 과정
- 데이터 분석 - 엄청나게 많은 데이터로 유의미한 인사이트를 얻는 것
- 웹 사이트 자동화
- 인공지능 학습 데이터
웹 크롤링 주요 활용 사례
- 상품, 콘텐츠 자동 업로드: 온라인 사업하시는 분들이 많이 사용함
- 부동산 주식 재테크 데이터 수집
- 인스타그램, 유튜브 모니터링 및 분석
- 뉴스 데이터 수집
- 논문, 구인 공고 데이터 수집
웹 페이지를 어떻게 볼 수 있을까?
- http 통신을 통해 볼 수 있다.
- 웹 브라우저(크롬, 파이어폭스)와 웹 서버(웹사이트에 대한 정보 제공) 사이에 데이터를 주고받는 데 사용되는 통신
- 클라이언트가 요청하면 html로 응답함
웹사이트 개발 3요소
- html: 구조
- css: 디자인
- JavaScript: 동작
html이란?
- Hyper Text Markup Language
- 웹사이트의 구조를 표시하기 위한 언어
태그 구조
<태그이름>내용</태그이름>- <시작태그> <종료태그>
<태그이름 속성=”속성값”>내용</태그이름>- 속성(attribute):태그의 추가적인 정보
- 속성은 여러 개 부여할 수 있다.
- 속성은 없어도 된다.
- 내용에는 텍스트나 태그가 들어갈 수 있다.
- 내용은 없어도 된다.
관계를 나타내는 용어
- 부모태그 / 자식태그
주석(comments)
<!-- 주석내용 -->- 코드에 메모를 표시할 때 사용한다.
- 코드를 실행하고 싶지 않을 때 사용한다.
<!DOCTYPE html> <!--웹 브라우저한테 html5로 작성 했다고 알려줌-->
<html lang="en">
<head>
<!--문서의 잡다한 정보-->
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>스타트핏: 운동의 시작</title><!--웹 페이지의 제목-->
</head>
<body>
<!-- 화면에 표시되는 내용 -->
<h1>스타트핏: 운동의 시작</h1>
<div><!--구역을 나타내는 태그-->
<h1>기초 체력업! 무분할 루틴</h1>
<p><!--문단을 나타내는 태그-->
운동을 처음 시작하는 헬린이 모여
</p>
<a href="https://naver.com">지금 시작하기</a>
</div>
<div><!--구역을 나타내는 태그-->
<h1>초보탈출! 3분할 루틴</h1>
<p><!--문단을 나타내는 태그-->
운동좀 했니? 드루와
</p>
<a href="https://naver.com">지금 시작하기</a>
</div>
<div><!--구역을 나타내는 태그-->
<h1>나만의 운동 목표 설정</h1>
<input type="text" placeholder="목표 입력">
<button onclick="alert('gogo!')">저장하기</button>
<ul>
<li><a href="#">웨이트</a></li>
<li><a href="#">유산소</a></li>
<li><a href="#">필라테스</a></li>
</ul>
</div>
</body>
</html>css 기본 문법
h1{color:red;}- 선택자 선언시작 속성명:속성값;선언종료
선택자(selector)
- 웹페이지에서 원하는 태그를 선택하는 문법
- 태그 선택자
- 태그 이름으로 선택하는 것
- 태그선택자는 다른 선택자와 결합해서 사용
- 클래스 선택자
- 클래스 속성 값으로 선택하는 것
- 클래스: 태그에 별명을 주는 것
- .클래스명
- 아이디 선택자
- 아이디 속성 값으로 선택하는 것
- 아이디: 태그에 별명을 주는 것
- #아이디명
- 자식 선택자
- 바로 아래 자식태그를 선택하는 것
- 내가 원하는 태그에 별명이 없을 때 사용
- 부모태그 > 자식태그
- 부모클래스 > 자식태그
<!DOCTYPE html>
<html lang="en">
<head>
<title>스타트핏: 운동의 시작</title>
<style>
a { color: red; }
#main-title { color: orange; }
.sub-title { font-size: 24px;}
.boxs { background-color: steelblue; padding: 15px; margin-bottom: 20px; border-radius: 5px;}
.boxs > a {color: white;}
.boxs > p {color: skyblue;}
</style>
</head>
<body>
<h1 id="main-title">스타트핏: 운동의 시작</h1>
<div class="boxs">
<h1 class="sub-title">기초 체력업! 무분할 루틴</h1>
<p>운동을 처음 시작하는 헬린이 모여</p>
<a href="https://naver.com">지금 시작하기</a>
</div>
<div class="boxs">
<h1 class="sub-title">초보탈출! 3분할 루틴</h1>
<p>운동좀 했니? 드루와</p>
<a href="https://naver.com">지금 시작하기</a>
</div>
<div class="boxs">
<h1 class="sub-title">나만의 운동 목표 설정</h1>
<input type="text" placeholder="목표 입력">
<button onclick="alert('gogo!')">저장하기</button>
<ul>
<li><a href="#">웨이트</a></li>
<li><a href="#">유산소</a></li>
<li><a href="#">필라테스</a></li>
</ul>
</div>
</body>
</html>웹 크롤링 기초
- 정적 페이지(static page) 크롤링
- 데이터의 추가적인 변경이 일어나지 않는 페이지(응답받는 HTML에 원하는 정보가 들어있음)
- 동적 페이지
- 데이터의 추가적인 변경이 일어난 페이지
정적페이지 크롤링 방법
- 데이터 받아오기
- 파이썬에서 서버에 요청을 보내고 응답받기
- HTTP통신으로 HTML을 받아오기
- HTML에서 원하는 부분만 추출
- CSS 선택자를 잘 만드는 것이 핵심

- response.status_code 출력 시
- 200: 통신 성공
- 404: 페이지 찾을 수 없음
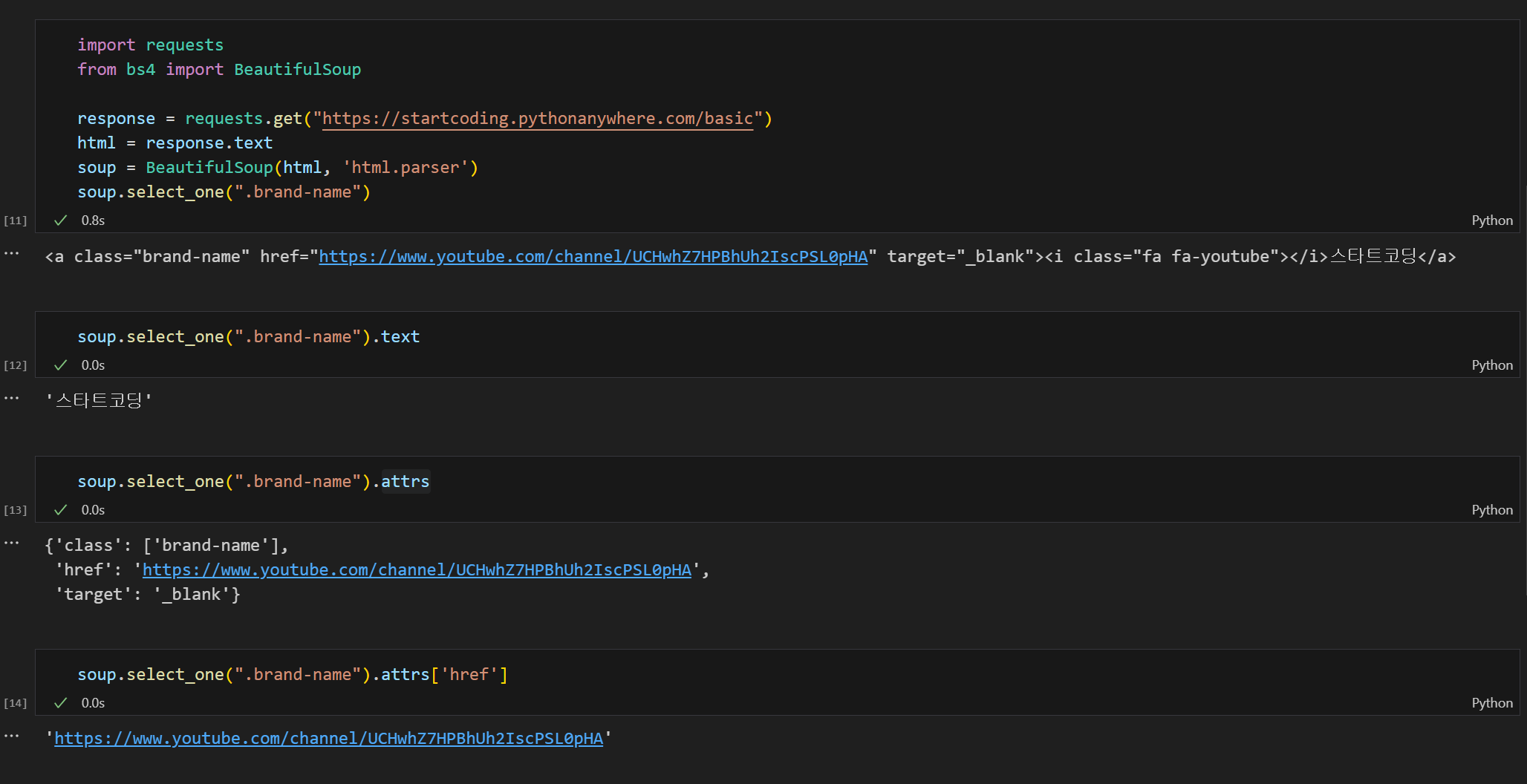
- 문자열 형태의 html을 html.parser라는 것이 태그 객체로 하나하나씩 잘라 soup에 담아 둔다.
- 객체 : 데이터+명령어 모두 가질 수 있는 자료형
- select_one: 매칭되는 태그 중 첫 번째 반환
한 개의 상품 크롤링

- strip(): 앞뒤 공백 제거

- replace(’ 변경 전 문자’, ‘변경 후 문자’): 문자열 교체

한 개의 상품 크롤링 결과

여러 개의 상품 크롤링
포레스트 이론
- 숲: 체이지 전체 HTML
- 나무: 원하는 정보를 모두 담는 태그
1. 숲에서 원하는 정보를 모두 담고 있는 나무를 찾는다.
- 나무태그 찾는 법
- 태그 하나를 찾는다.
- 상위태그(부모태그)를 찾아 올라간다.
- 원하는 정보를 모두 담고 있는지 확인한다.
2. CSS 선택자를 만들어 테스트한다.
3. soup.select(”CSS선택자”)로 숲에서 나무를 뽑는다.
- select(): 선택자에 매칭되는 태그 전체를 리스트로 반환
4. 반복문을 돌면서 나무에 하나씩 열매를 추출한다.

여러 개의 상품 크롤링 결과

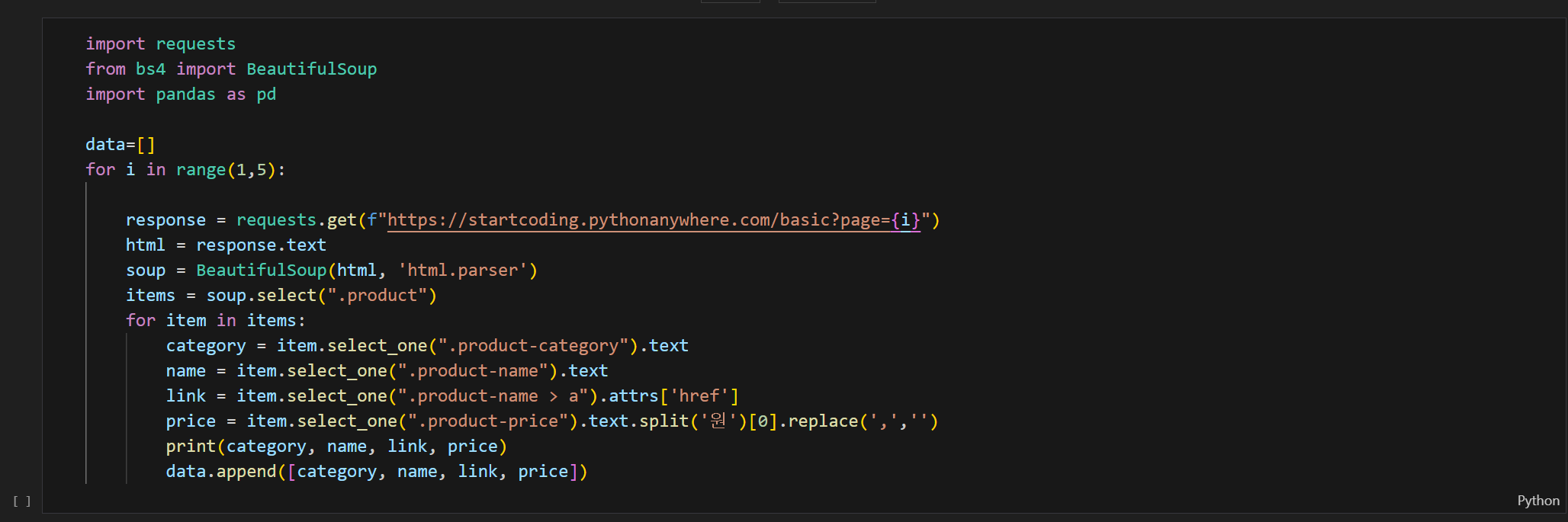
여러 페이지 크롤링
URL(Uniform Resource Locator)
- 인터넷 주소 형식
- Protocol - Domain - Path - Parameter
http://www.naver.com/search.naver?where=news&query=test- Protocol //Domain/Path?Parameter(key=value&key=value)
- Parameter: 서버에 추가정보 제공
페이징 알고리즘
1. 페이지를 바꾸면서 URL이 변경되는 부분을 찾는다.
2. 페이지를 증가시키면서 요청을 보낸다.
- value 값이 없는 파라미터는 지워도 된다.
3. 문자열과 변수(데이터) 합쳐서 새로운 문자열을 만들고 싶을 때 사용
여러 페이지 크롤링 결과

데이터엑셀에 저장
1. 라이브러리 설치
- pip install pandas: 데이터분석 라이브러리
- pip install openpyxl: 엑셀 자동화 라이브러리

2. 비어있는 리스트를 만들고 데이터를 한 행씩 추가한다.
3. 데이터 프레임을 만든다.

4. 엑셀에 저장한다.
- 인덱스 있이 엑셀 저장

- 인덱스 없이 엑셀 저장

AttributeError:’NoneType’ 에러 발생
더보기
동적페이지 일 경우가 높음
- 데이터의 추가적인 변경이 일어나는 페이지
- 응답받는 HTML에 원하는 정보가 들어있지 않음
- 셀레니움 라이브러리 활용하면 됨
후기
- 웹 개발을 진행하면서 크롤링을 할 경우가 있는데 강의를 듣기 전까지 웹 크롤링의 기초에 대해 정확히 몰라 필요할 때마다 찾아보곤 했었다.
- 강의를 들으면서 웹 크롤링을 어떻게 하면 되는지 엑셀로 저장 시 어떤 라이브러리를 사용해야 하는지 알 수 있었다.
728x90
반응형